Written by Steven Woo
As we discussed in our previous blog post, there is a sense of growing concern in the high-performance computing (HPC) space over successive generations of supercomputers that have continued to move further and further away from architectural balance between compute and memory resources. This is because compute performance has improved at significantly faster rates than memory and I/O subsystems.
Amdahl’s Rule of Thumb
Gene Amdahl, who gained fame for his seminal work on diminishing returns that became known as Amdahl’s Law, formulated a lesser known second principle that is sometimes referred to as ‘Amdahl’s Rule of Thumb’ or ‘Amdahl’s Other Law.’ This second principle addresses the importance of architectural balance and stipulates a 1:1:1 ratio of FLOPs to Memory Bandwidth to IO bandwidth. With an ideal target of one byte of memory needed per FLOP (matched by one byte of transfer over an external interface), Amdahl believed that computer systems could remain in balance.
The move away from this 1:1:1 ratio, and hence from balanced architectures, has been an ongoing concern among high-performance computer system architects over the past two decades. In his keynote talk at Supercomputing 2016 (SC16), John McAlpin of the Texas Advanced Computing Center presented data illustrating how systems are becoming more unbalanced with each new generation.
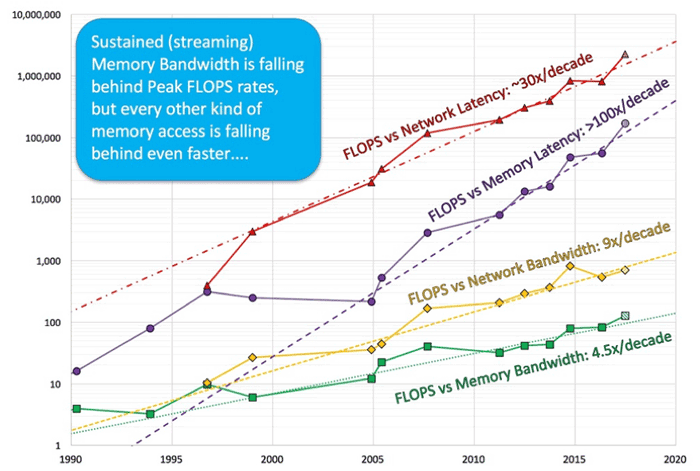
Source: https://www.hpcwire.com/2016/11/07/mccalpin-traces-hpc-system-balance-trends/
Based on the period from 1990-2016, the trends shown in the image above illustrate the stark nature of this growing imbalance: the ratio of FLOPs to memory bandwidth is growing at a rate of 4.5X per decade, while the ratio of FLOPs to network bandwidth is increasing at a rate of 9X per decade. Measured as a function of memory and network latency, the growth rates are even more severe: the ratio of FLOPs to memory latency is growing at a rate of more than 100X per decade, while the ratio of FLOPs to network latency is increasing at a rate of ~30X per decade.
Improving HPC Memory Hierarchies
With such astonishing rates of growth in architecture imbalance, the critical question has become how to feed the compute pipeline in the most economical, power-efficient manner to achieve the ExaFLOP performance targeted by next-generation supercomputers. Improved memory hierarchies and more power-efficient memory systems are the focus for addressing the growing imbalance relative to memory performance. Having fallen so far behind the ratios needed to maintain true balance, supercomputing memory systems could clearly benefit from any improvements in memory bandwidth and latency.
However, there is an industry-wide realization that simply keeping up with the historic trend of doubling memory bandwidth and improving power efficiency every generation will be even more challenging going forward. Clearly, new approaches are needed to improve memory hierarchies that move in the direction of restoring balance to high performance computing system architectures. The increased use of HBM memory in the HPC space is one such potential approach that could help address the demand for more memory system performance with improved power efficiency. While HBM memory is more challenging to design into systems than other memories such as DDR and GDDR, the benefits for HPC systems are so compelling that it is being introduced into future high-performance computing systems in Japan.
More specifically, the Post-K Supercomputer will be comprised of nodes powered by Fujitsu’s A64FX CPU connected to four HBM DRAMs serving as the processor main memory. The NEC SX-Aurora Tsubasa platform provides a scalable computing solution capable of supercomputer-class performance using the company’s new Vector Engine card. The A500-64 supercomputer, built around this platform, uses 64 Vector Engines that include a high-performance vector processor connected to six HBM DRAMs that provide unprecedented levels of memory bandwidth.
HPC Cores and Clock Frequencies
Although next-generation HPC processor architectures have yet to be finalized, preliminary investigations conducted in research under the US’s next-generation supercomputer program indicate that while the number of processing cores on a chip are expected to increase, the clock frequencies of the cores may potentially decrease to conserve power. Concurrency at the level of billion-way parallelism is also a possibility – and application-level parallelism will be critical to achieving Exascale performance on these machines. At this scale, reliability and resiliency will also be critical. HPC applications may run for weeks or months on these machines, so silent errors that propagate through iterative computations will render the machines useless if not identified in a timely manner. Consequently, methods for improving memory and link reliability and resilience will only grow in importance.
Leave a Reply