Frank Ferro, Senior Director Product Management at Rambus, and Shane Rau, Senior Research Executive at IDC, recently hosted a webinar that explores the role of tailored DRAM solutions in advancing artificial intelligence. Part two of this four-part series touched on multiple topics including how AI enables useful data processing, various types of AI silicon, and the evolving role of DRAM. This blog post (part three) takes a closer look at the impact of AI on specific hardware systems, training versus inference, and selecting the most appropriate memory for AI/ML applications.
Impact of AI on Specific Hardware Systems
According to Ferro, a lot of the hardware driving the internet is general-purpose compute hardware, along with some graphics GPUs. These, says Ferro, have adapted over the years to support the requirements of AI processing. However, we are now seeing many companies design specific processors that are custom tailored to support AI applications.
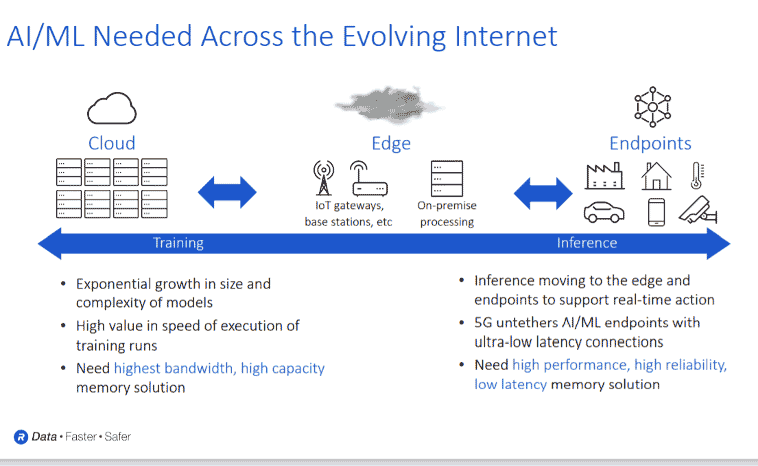
“For example, if you look at the cloud, there are high compute-intensity types of applications with data that is gathered and processed. We’re calling these AI training type algorithms, where you have different neural networks that need to be trained to understand the data,” he explained. “As you move through the network, you have endpoints that are pumping the data up. A good example is Amazon Alexa, which processes the data up into the cloud and moves the data across the network. Moving forward, this paradigm can potentially overwhelm the network as data loads increase. So, we need to do much more inline processing.”
The requirements of local processing at home via devices such as Alexa, says Ferro, will ultimately require significantly more processing capability and memory bandwidth capacity.
“For example, at an endpoint, you’re going to need 50-100 megabytes of processing to deal with all that data locally. To do that, you are going to need memory systems that are a little bit beyond what is available and what has been traditionally available,” he elaborated. “If you look at the edge of the network, 5G as well, there will be much more inline processing. If you move the data from your endpoint through the network, you will want to do as much processing at each of those end points. So, more memory capacity will be needed.”
Typically, says Ferro, the data is moved through a 5G base station. However, some data will ultimately be processed in the base station, as well as in the cloud, where a significant amount of processing power will be required to handle terabytes of data.
Training Versus Inference
To illustrate the difference between AI training and inference, Ferro points to the slide below that highlights training and inference requirements.
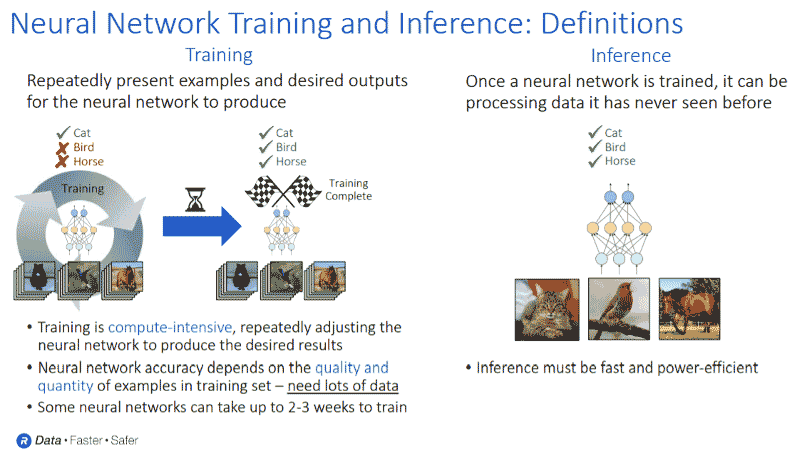
“Training relates to inputting a large amount of data into the network to make sure it understands what you’re specifically trying to identify. If you’re dealing with a car or some other critical real time system, for example, you want to make sure that you get the answer right,” he explains. “This can take many, many iterations of data and good quality data processing. Some of these networks can take days and even weeks to train and requires a lot of bandwidth and a lot of capacity on the DRAM.”
Once those models are trained, says Ferro, they can be pushed out into the network or used for local processing.
“That’s what we call inference, which has a much lower processing requirement,” he adds.
Choosing the Correct Memory for AI/ML
In terms of choosing memory systems for AI, Ferro said some memory systems are more effective for training, while others are better suited for inference.
“For inference, you can think of an endpoint, whether it is a car or consumer device. There will also be a number of different requirements. For example, you are going to want the endpoint and memory system to be power efficient, cost efficient, and process very quickly,” he elaborates. “Up in the network, it may not be the same level of real-time processing, and you’re going to need more processing power. So, there are different costs related to memory density and performance.”
To illustrate the various types of memory systems for AI applications, Ferro points to the slide below and highlights LPDDR4X.
“LPDDR4X, which was traditionally used in mobile applications, provides high speeds at 17 gigabytes per second of processing. It offers low power and very good efficiency. It has migrated away from only being used in mobile devices. In addition to mobile, LPDDR4X is now used in applications like automotive. This is because LPDDR4X provides some additional processing and power efficiency in automotive applications – and even in some low-end AI inference applications.”
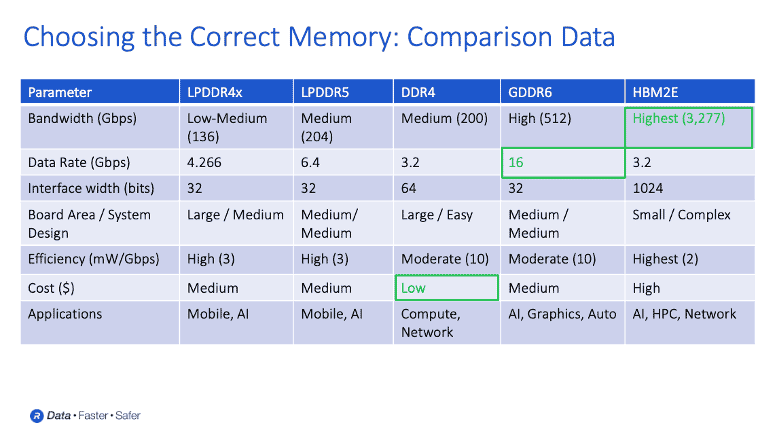
Note: On Sep. 9, 2020, Rambus announced its HBM2E interface could operate at 3.6 Gbps raising bandwidth to 3,686 Gbps (461 GB/s).
According to Ferro, GDDR6 has also stepped out of the graphics and gaming worlds and is now used for “in-between applications” such as AI inference and automotive systems. HBM, says Ferro, is used in higher-end applications, offering gigabytes per second of processing power.

“As of today, most of the systems are very heavily slanted towards DDR because that was the only available memory standard. But you can see at 3.2 gigabits per second, DDR is just starting to run out of steam,” he explains. “It’s a great DRAM still being used in many, many systems, and very price efficient. However, these AI systems are simply demanding more and more bandwidth, and in some cases, capacity as well. This gives rise to the need for new memory systems.”
In the slide above, Ferro provides more details about where HBM and GDDR6 are deployed in the marketplace.
“HBM’s focus market has been high performance computing and the more performance you need, HBM is usually the memory of choice. As well, HBM is used for AI training and network applications. 5G systems need to do much more processing and HBM is starting to emerge as a solution in the network anywhere you need very high bandwidth and good capacity,” he elaborates. “As well, GDDR6 is emerging from the graphics world. Not because HBM wasn’t a good solution, but customers and systems needed something that was a little bit more cost efficient, maybe a little bit less complex to manufacture.”
According to Ferro, GDDR6 offers a “really good” trade-off between performance, cost and system complexity. As such, GDDR6 is a popular choice for AI inference, graphics and automotive applications.
“The processing requirements for automotive AI are going up, but you can’t put HBM into a car right now because of some of the reliability concerns with the manufacturing of these 3D structures. However, GDDR6 is a really good solution – giving you both the speeds you need and easier design complexity, which matches nicely for automotive,” he concludes.
Leave a Reply