In part three of this series, we discussed how a Roofline model can help system designers better understand if the performance of applications running on specific processors is limited more by compute resources, or by memory bandwidth. Rooflines are particularly useful when analyzing machine learning applications like neural networks running on artificial intelligence (AI) processors. In this blog post, we’ll be taking a closer look at a Roofline model that illustrates how AI applications perform on Google’s tensor processing unit (TPU), NVIDIA’s K80 GPU and Intel’s Haswell CPU.
The graph above is featured in a paper published by Google a couple of years ago detailing the first-generation Tensor Processing Unit (TPU). It’s a very insightful paper, because it compares the performance of Google’s TPU against two other processors. You can see three different Rooflines in the graph above: one in red, one in gold and one in blue. The blue Roofline represents the Google TPU, a special purpose-built piece of silicon that was specifically designed for AI inferencing. The NVIDIA K80 – a GPU designed to handle a larger class of operations – is in red. Represented in gold is the Roofline for the Intel Haswell CPU, a very general-purpose processor.
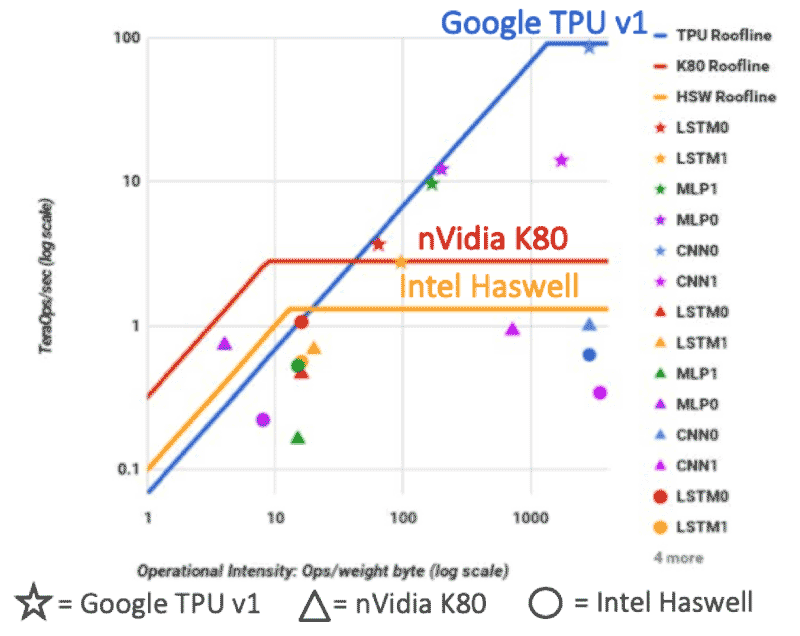
Source: N.Jouppi, et.al., “In-Datacenter Performance Analysis of a Tensor Processing UnitTM,” https://arxiv.org/ftp/arxiv/papers/1704/1704.04760.pdf
In the Google paper, 6 neural networks were coded for each of the different architectures. The stars show the architectures of neural networks that were coded for the Google TPU. The triangles are the same neural network architectures coded for the NVIDIA K80, while the circles are the same neural network architectures coded for the Intel Haswell processor. When you look at the neural networks running on the Intel Haswell and the NVIDIA K80, you will observe that many of the circles and triangles are under the flat part of the respective Rooflines – and many of them are under the slanted part of these Rooflines. This means some of the neural networks are limited by memory bandwidth, while others are more limited by compute performance for these processor architectures.
However, when you look at the stars you see the majority lie on or under the sloped part of the Roofline for the Google TPU. This placement tells us that memory bandwidth is a critical bottleneck for machine learning applications running on these purpose-built AI processors. In fact, it’s part of the reason why Google used HBM (the highest bandwidth discrete DRAM memory available at the time) in future versions of the TPU. So, we can certainly infer that memory bandwidth is critical for AI silicon and applications.
Since memory is an important resource for AI chips, it is essential to make the best use of available bandwidth. Indeed, traditional scientific calculations are frequently executed as 32-bit and 64-bit floating point numbers. However, modern research has shown this level of precision isn’t needed to achieve good performance for machine learning applications. It turns out that many architectures use reduced precision, so instead of executing all calculations with 32-bit numbers, sometimes 16-bit, 8-bit, or even fewer bits are used. This approach of utilizing “reduced precision” numbers has the benefit of maximizing available bandwidth, because you can squeeze in more numbers, as each number now takes fewer bits to encode.

Leave a Reply